

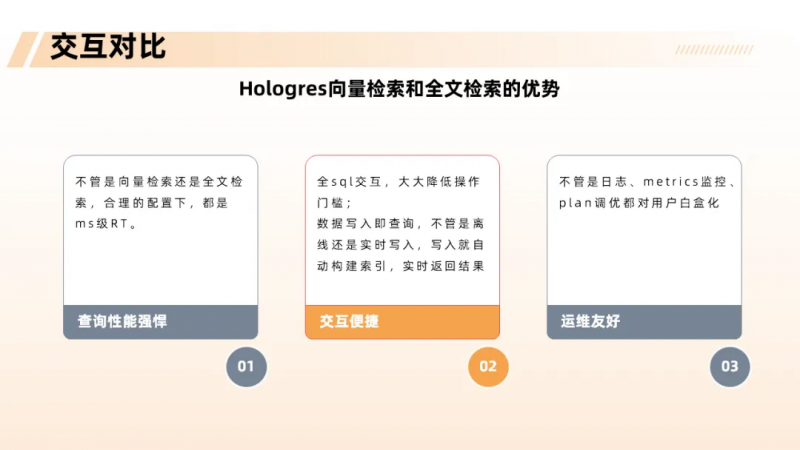
Hologres 向量检索和全文检索在淘天客户运营的实践
速发资讯 2026-02-26 user795653
在淘天集团(淘宝天猫)客户运营团队的数据实践中,随着AI应用的深入落地,如何高效、准确地从海量非结构化文本中召回相关知识,成为支撑智能客服、规则比对、舆情分析等关键业务场景的核心技术挑战。面对这一需求,淘天客户运营团队基于 Hologres 构建了一套融合向量检索与全文检索的一体化解决方案,并已在多个业务场景中取得显著成效。
为何需要向量检索与全文检索?
在大模型时代,本地知识库成为增强模型能力的重要手段。然而,当知识规模达到数十万甚至上百万条时,传统的本地知识管理方式难以维护;而通过 SQL 中的 LIKE 或正则表达式进行关键词匹配,不仅规则难以穷举、匹配精度低,且在大规模数据下性能堪忧——查询响应常达数秒,无法满足线上服务的实时性要求。

为解决这一问题,团队引入了两种互补的检索范式:全文检索与向量检索。全文检索基于关键词匹配,通过对文本内容进行分词并建立倒排索引,实现毫秒级的快速召回。例如,用户输入“我在杭州很想你”,系统可精准匹配包含“杭州”“想你”等关键词的知识条目。然而,关键词本身缺乏语义理解能力——当用户提问“水果有哪些?”,仅靠关键词无法召回“苹果”“香蕉”等具体实例。
此时,向量检索的价值凸显。通过将文本嵌入为高维向量(如128维),系统可基于语义相似度进行召回,实现“水果”与“苹果”之间的语义关联。在实际应用中,团队通常将两种检索方式结合使用:先通过向量检索获取语义相近的结果,再辅以全文检索补充关键词匹配项,最终将融合后的结果送入大模型进行推理与生成,形成完整的 RAG(Retrieval-Augmented Generation)流程。
为何选择 Hologres?

面对上述需求,团队最终选择 Hologres 作为底层引擎,主要基于三方面考量:
首先,Hologres 具备强大的实时数仓与 OLAP 能力,不仅支持向量与全文检索,还能在同一张表中无缝集成标量过滤、多字段排序、复杂 JOIN 等分析操作,极大提升了方案的扩展性与灵活性。
其次,自 4.0 版本起,Hologres 推出了自研的 HGraph 向量索引,替代了早期依赖的达摩院 Proxima。在千万级数据量下,HGraph 的平均响应时间从 Proxima 的4秒降至30毫秒,性能提升两个数量级。同时,Hologres 还内置了全文检索能力,支持中文分词、AND/OR 逻辑匹配、写入即查等特性,真正实现“一张表、一套引擎、两种检索”。

最后,稳定性与运维体验是长期落地的关键。淘天客户运营团队自 Hologres 1.0 版本起便深度使用,见证了其从初期稳定性不足到如今支持多资源组、Serverless 计算、热扩容与热升级的演进。近两年,在业务用量持续增长的同时,稳定性问题显著减少,为高可用线上服务提供了坚实保障。
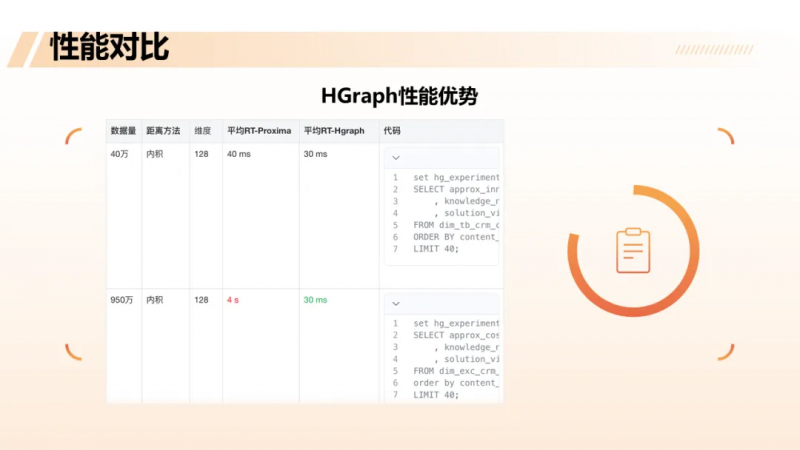
HGraph vs Proxima:性能跃升

在向量检索引擎选型中,团队对 HGraph 与 Proxima 进行了实测对比。在40万条、128维内积向量的场景下,两者性能差异尚不明显(Proxima 约40ms,HGraph 约30ms)。但在950万条(近千万级)数据下,Proxima 的平均 RT 飙升至4秒,而 HGraph 仍稳定在 30毫秒左右——仅指纯向量召回阶段,若叠加后续 OLAP 操作(如过滤、排序),整体延迟通常控制在数百毫秒内,完全满足业务需求。
使用 HGraph 极为简便:只需在建表时声明向量字段维度(如knowledge_vectors array
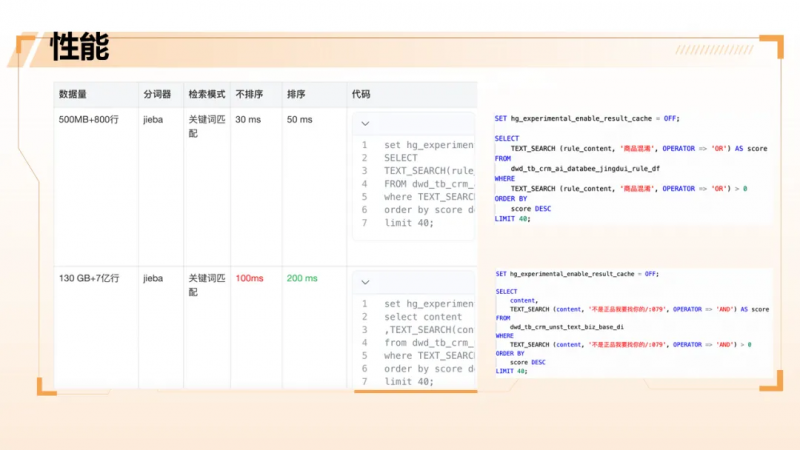
全文检索:简单高效,写入即查
Hologres 的全文检索同样表现出色。系统采用 jieba 分词器 对中文文本进行分词,并构建倒排索引。在小数据量但长文本的场景中,简单查询可实现30余毫秒响应;即便在7亿条数据、复杂 AND 匹配、带排序的条件下,响应时间也仅约200毫秒,完全满足线上服务 SLA。
使用流程同样简洁:创建列存表后,对目标文本字段构建全文索引。若索引在写入前创建,则数据写入后自动触发 compaction,实现“写入即可查”;若先写入后建索引,则需手动执行 compaction(需注意资源水位,避免影响线上服务)。查询时可通过TEXT函数封装关键词,并指定OR(默认)或AND逻辑。同样,通过EXPLAIN ANALYZE观察是否命中Fulltext Filter,可确认索引生效。
相比 Elasticsearch 等传统全文引擎,Hologres 的配置更为直观,无需理解复杂的 JSON 参数,大幅降低使用门槛。同时,其与 OLAP 能力的原生集成,使得“检索+分析”一体化成为可能。
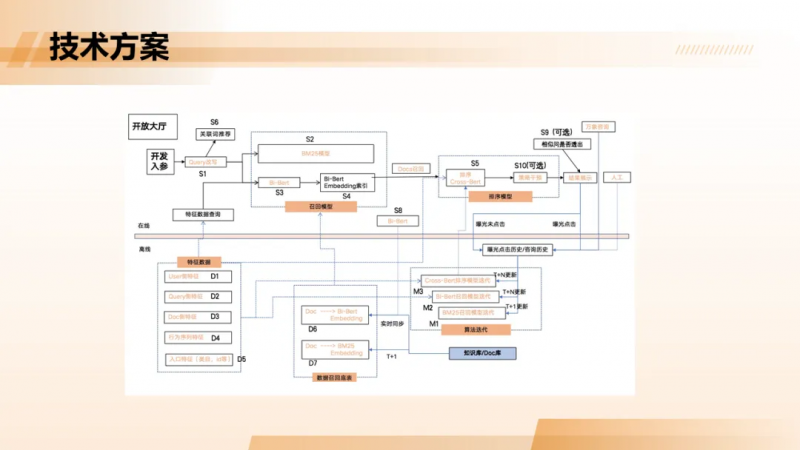
整体技术方案
该方案整体分为三个阶段:准备阶段、检索阶段与应用阶段。
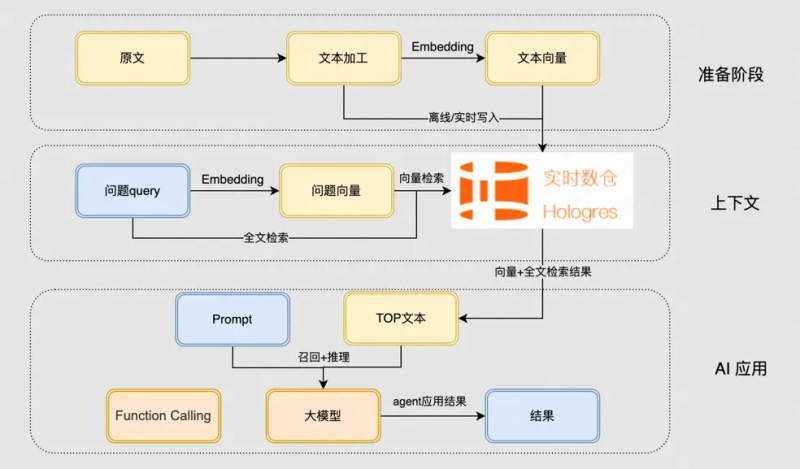

在准备阶段,原始文本(如客服知识、平台规则)经过清洗、规则增强(如生成相似问)后,分别通过 Embedding 模型生成向量,并保留原始文本用于全文索引。随后,向量与文本一同写入 Hologres 同一张表中,系统自动构建 HGraph 与全文索引。
在检索阶段,用户 Query 被同时送入 Embedding 模型与分词器,生成向量与关键词,分别触发向量检索与全文检索。两路结果可加权融合或独立使用,最终召回 Top-K 相关文档。
在应用阶段,召回结果作为上下文输入大模型,结合 Prompt 工程与工具调用(如规则比对、订单查询),生成最终答案或决策建议,服务于智能客服 Agent、规则分析平台等上层应用。
场景一:商家求助知识召回
在客服场景中,消费者或商家通过小蜜或者商家服务大厅发起咨询,期望在最前端智能侧准确解答,避免转接人工。团队基于 Hologres 构建了融合向量与全文检索的知识召回系统。
具体流程如下:用户进线后,系统首先对 Query 进行 Embedding 生成向量,并进行分词处理。随后,向量检索与全文检索并行执行,分别从知识库中召回语义相近和关键词匹配的解决方案。召回结果(通常为20-40条)被送入大模型应用,结合精心设计的 Prompt 进行推理与精排,最终生成精准回答。该方案部署在整个客服链路的最前置环节,显著提升了智能解决率。相比早期基于 LIKE/正则的方案,新系统不仅响应更快,且能有效处理语义泛化问题(如“退款”可召回“仅退款”“退货退款”等细分场景),大幅优化用户体验。实际运行数据显示,该方案在召回率、点击率与准确率等核心指标上均有显著提升。
场景二:友商规则全文检索
在平台规则制定中,需定期分析友商的规则变更(如退货赔付标准),以调整自身策略。由于规则文本多为半结构化,格式不一,传统规则匹配难以覆盖。
团队构建了基于 Hologres 全文检索的规则分析系统:通过爬虫采集规则,清洗后存入 Hologres 并建立全文索引。用户输入检索意图(如“查看各平台关于7天无理由退货的规定”),系统召回相关条款,再由大模型进行对比总结,最终在前端展示结构化对比结果。
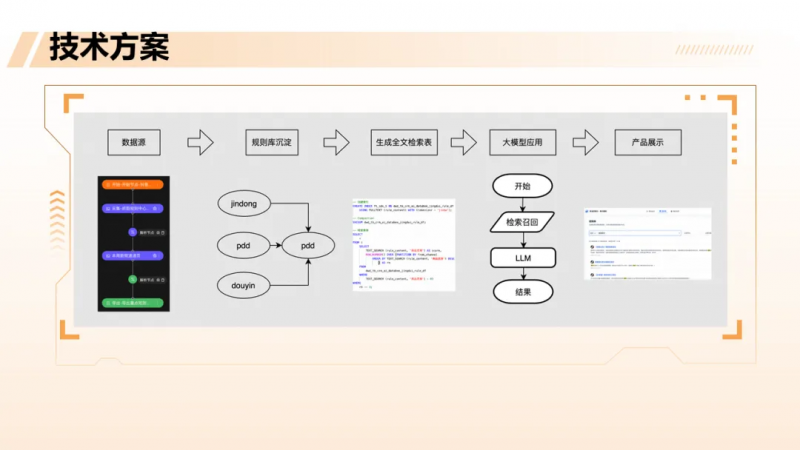
该方案将原本秒级甚至超时的正则匹配,优化至500毫秒内返回,且召回率显著提升,解决了大量因关键词变异导致的漏召问题。

未来展望
尽管当前方案已取得良好效果,团队仍对 Hologres 提出进一步期望:
在业务层面,计划将该能力拓展至舆情分析与相似案例聚类场景。例如,通过图像识别提取用户在社交平台发布的客服聊天截图,再结合向量与全文检索,精准定位原始对话及关联订单,辅助质检与根因分析;或对客服历史对话进行相似案例召回与聚类,提炼共性问题,优化服务策略。

在能力层面,希望 Hologres 能进一步简化使用链路:一是支持内置 Embedding 函数,避免业务方依赖外部模型服务;二是允许全文检索的查询参数为变量(而非仅常量),以支持动态查询场景;三是优化增量 compaction 机制,使异步 compaction 也能走 Serverless 资源组,避免对在线服务造成资源冲击。
综上,Hologres 凭借其一体化的向量与全文检索能力、卓越的性能表现及稳定的工程体验,已成为淘天客户运营团队构建智能检索系统的首选引擎。随着更多场景的落地与能力的持续演进,其在 AI 时代的基础设施价值将进一步凸显。
The End
免责声明:本文内容来源于第三方或整理自互联网,本站仅提供展示,不拥有所有权,不代表本站观点立场,也不构成任何其他建议,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容,不承担相关法律责任。如发现本站文章、图片等内容有涉及版权/违法违规或其他不适合的内容, 请及时联系我们进行处理。
-
分类导航
-
-
最新文章
-
本栏文章
-
随机文章
-
友情链接
